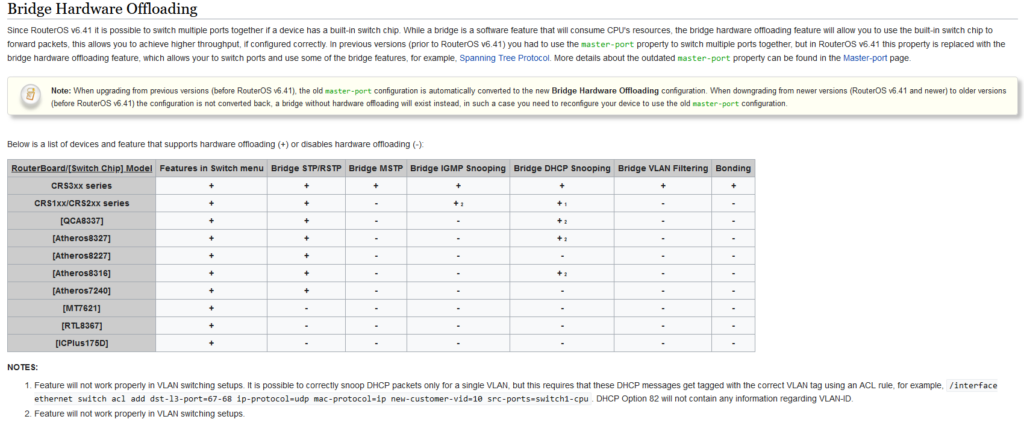
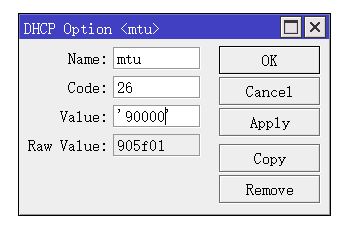
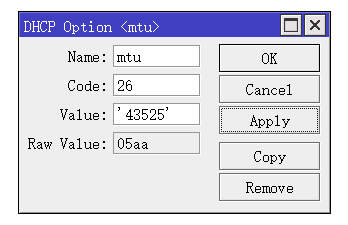
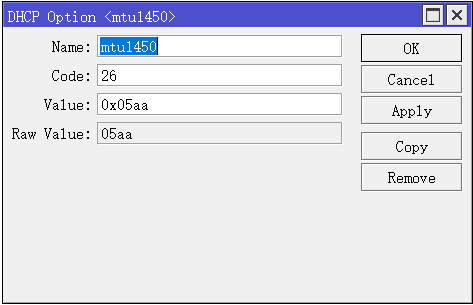
刚整了个AgentDVR,里面设置支持GPU解码,于是寻思着整一个,因为J4125的CPU带6路视频录像确实有点吃力,即使是使用了摄像头的stream2,用的是低分辨率的视频流来进行分析,对这个轻量级的CPU来说还是有点吃力。
于是进行了一番Google之后,顺利实现,下面记录一下过程。注意的是,我这里使用的是intel的核显,也就是vaapi,如果是AMD或者Nvidia的显卡的话,肯定会有点不一样,具体的差别需要继续搜索。
宿主机安装驱动
首先,安装显卡驱动和相关的查看工具
apt install i965-va-driver intel-media-va-driver vainfo
根据包的说明i965-va-driver是给Intel G45 & HD Graphics的显卡驱动,而intel-media-va-driver是8代之后的显卡驱动,可以根据实际情况酌情选择。至于vainfo,就是查看相关信息的工具。安装之后执行vainfo,可以看到显卡的加速信息:
root@pve4:~# vainfo
error: can't connect to X server!
libva info: VA-API version 1.10.0
libva info: Trying to open /usr/lib/x86_64-linux-gnu/dri/iHD_drv_video.so
libva info: Found init function __vaDriverInit_1_10
libva info: va_openDriver() returns 0
vainfo: VA-API version: 1.10 (libva 2.10.0)
vainfo: Driver version: Intel iHD driver for Intel(R) Gen Graphics - 21.1.1 ()
vainfo: Supported profile and entrypoints
VAProfileMPEG2Simple : VAEntrypointVLD
VAProfileMPEG2Main : VAEntrypointVLD
VAProfileH264Main : VAEntrypointVLD
VAProfileH264Main : VAEntrypointEncSliceLP
VAProfileH264High : VAEntrypointVLD
VAProfileH264High : VAEntrypointEncSliceLP
VAProfileJPEGBaseline : VAEntrypointVLD
VAProfileJPEGBaseline : VAEntrypointEncPicture
VAProfileH264ConstrainedBaseline: VAEntrypointVLD
VAProfileH264ConstrainedBaseline: VAEntrypointEncSliceLP
VAProfileVP8Version0_3 : VAEntrypointVLD
VAProfileHEVCMain : VAEntrypointVLD
VAProfileHEVCMain10 : VAEntrypointVLD
VAProfileVP9Profile0 : VAEntrypointVLD
VAProfileVP9Profile2 : VAEntrypointVLD
能看到显卡支持的编码,就算是成功了。这时候,可以在母机的/dev/dri/文件夹下面看到以下内容:
root@pve4:/etc/pve/lxc# ls -als /dev/dri
total 0
0 drwxr-xr-x 3 root root 100 Mar 12 16:22 .
0 drwxr-xr-x 23 root root 5140 Mar 17 07:40 ..
0 drwxr-xr-x 2 root root 80 Mar 12 16:22 by-path
0 crw-rw---- 1 root video 226, 0 Mar 12 16:22 card0
0 crw-rw---- 1 root render 226, 128 Mar 12 16:22 renderD128
将显卡透传给LXC容器
先给上两个参考文档:
简单来说,就是直接用文本编辑器修改lxc容器的配置文件,加上这么一块
lxc.cgroup2.devices.allow: c 226:0 rwm
lxc.cgroup2.devices.allow: c 226:128 rwm
lxc.mount.entry: /dev/dri/renderD128 dev/dri/renderD128 none bind,optional,create=file
lxc.mount.entry: /dev/dri/card0 dev/dri/card0 none bind,optional,create=file
根据proxmox论坛里面的说明,如果是proxmox 6或者之前的,就用lxc.cgroup。如果是Promox 7或者之后的,就用lxc.cgrpup2。保存退出。
启动LXC容器,再看看/dev/dri/就能看到已经挂载了:
root@ispy:~# ls -als /dev/dri
total 0
0 drwxr-xr-x 2 root root 80 Mar 17 09:44 .
0 drwxr-xr-x 8 root root 520 Mar 17 09:44 ..
0 crw-rw---- 1 nobody nogroup 226, 0 Mar 12 08:22 card0
0 crw-rw---- 1 nobody nogroup 226, 128 Mar 12 08:22 renderD128
然后,就是最后一个问题,权限问题,由于lxc容器有隔离,从上面的结果可以看到card0和renderD128被映射成了nobody:nogroup的ownership。这时候就有这么个几种解决办法:
简单粗暴,母机对两个设备给与666的权限
在母机上,直接运行
chmod 666 /dev/dri/card0 /dev/dri/renderD128
使得显卡所有人可以读写。但是这种方法存在一定的安全隐患,所以用来测试配置是否成功的时候可以用,测试OK的话,应该换个别的方法来赋予权限。
idmap+usermod
思路是这样,lxc容器有个设定,叫做idmap,用来控制容器内部的uid和gid如何映射到母机上对应的部分的。例如这个参考:https://bookstack.swigg.net/books/linux/page/lxc-gpu-access。
首先,考虑到两个设备默认的权限是660,所以我们有几个方向:
- 将LXC容器中需要调用显卡的用户映射为母机的root(明显有严重的安全隐患,而且无法处理多个用户需要调用显卡的情况,pass)
- 修改
/dev/dri/card0 /dev/dri/renderD128的ownership,然后和上面一样将LXC容器中需要调用显卡的用户映射为这个新的owner(也还行,但是同样无法处理多用户同时调用,而且母机系统的变动比较多) - 将LXC容器中的video组和render组映射到母机的video和render组,然后将需要调用显卡的用户都加入这两个组(不错,但是对于不同的系统,就需要检查对应的/etc/group,并进行对应的调整)
我选择第3种方法。
首先,要确认一下系统的video组和render组,首先是母机的,因为系统都是proxmox(debian),所以gid理论上都是一样的,video的gid是44,render是103:
root@pve4:/etc/pve/lxc# cat /etc/group
……
video:x:44:root
……
render:x:103:root
……
然后就是检查LXC容器的用户组,我用的是Ubuntu20.04,video是gid是44,render是107:
root@ispy:/# cat /etc/group
……
video:x:44:
……
render:x:107:
准备工作就做好了。接下来关掉容器,直接用文本编辑器修改LXC容器的配置文件,加入这么一块内容:
lxc.idmap: u 0 100000 65535
lxc.idmap: g 0 100000 44
lxc.idmap: g 44 44 1
lxc.idmap: g 45 100045 62
lxc.idmap: g 107 103 1
lxc.idmap: g 108 100108 65427
下面给一点解释:
lxc.idmap: u 0 100000 65535 //映射LXC容器中的uid,将容器中[0-65535)映射为母机的[100000-165535)
lxc.idmap: g 0 100000 44 //映射LXC容器中的gid,将容器中[0-44)映射为母机的[100000-100044)
lxc.idmap: g 44 44 1 //映射LXC容器中的gid,将容器中[44-45)映射为母机的[44-45)
lxc.idmap: g 45 100045 62 //映射LXC容器中的gid,将容器中[45-106)映射为母机的[100045-100106)
lxc.idmap: g 107 103 1 //映射LXC容器中的gid,将容器中[107-108)映射为母机的[103-104)
lxc.idmap: g 108 100108 65427 //映射LXC容器中的gid,将容器中[108-65535)映射为母机的[100108-165535)
然后就是要配置/etc/subgid文件,添加以下内容:
root:44:1
root:103:1
最后,把LXC容器开起来,将需要调用显卡的用户加入两个组:
root@ispy:/# usermod -G video root
root@ispy:/# usermod -G render root
执行测试
测试的方法和母机差不多,都是用vainfo来检查,或者使用ffmpeg来测试,但这两个都需要安装一堆软件包,所以这时候,先给容器打个快照。
vainfo的方法可以参考母机,不同的发行版有不同的包管理器,安装vainfo然后运行就能看到结果了。
另外一个方法是使用ffmpeg,这个更接近实际应用,毕竟很多应用也是通过调用ffmpeg来执行编解码的操作。具体ffmpeg的使用方法可以参考官方的文档。
这里给出比较有用的一个参考:
ffmpeg -hwaccel vaapi -hwaccel_output_format vaapi -i input.mp4 -f null -
这样可以让ffmpeg调用vaapi来进行解码,并且不输出任何东西,如果能够顺利解码,那就算是成功了。
LXC透传给Docker
透传给Docker的部分不算非常困难,只需要在docker-compose文件里面加上这么一节就可以透进去了:
version: '2.4'
services:
agentdvr:
image: doitandbedone/ispyagentdvr
restart: unless-stopped
environment:
- TZ=Asia/Shanghai
ports:
- 8090:8090
- 3478:3478/udp
- 50000-50010:50000-50010/udp
volumes:
- ./ispyagentdvr/config:/agent/Media/XML
- ./ispyagentdvr/media:/agent/Media/WebServerRoot/Media
- ./ispyagentdvr/commands:/agent/commands
devices:
- /dev/dri:/dev/dri
但是我们遇到了和LXC透传的时候一样的问题,文件权限的问题。ispy提供的docker镜像是基于Ubuntu18.04的,
root@34c54716eee7:/# ls -las /dev/dri
total 0
0 drwxr-xr-x 2 root root 80 Mar 17 17:44 .
0 drwxr-xr-x 6 root root 360 Mar 17 17:44 ..
0 crw-rw---- 1 nobody video 226, 0 Mar 12 16:22 card0
0 crw-rw---- 1 nobody 107 226, 128 Mar 12 16:22 renderD128
root@34c54716eee7:/# cat /etc/group
root:x:0:
……
video:x:44:
……
messagebus:x:102:
容器里面就没有render组,root用户也不在两个用户组里面。于是还得自己build一下镜像……
root@ispy:~/agentdvr# cat build/Dockerfile
FROM doitandbedone/ispyagentdvr
RUN groupadd -g 107 render
RUN usermod -g 44 root
RUN usermod -g 107 root
完了之后就可以在docker 容器中调用GPU进行加速了。